
Why (most) High Level Languages are Slow
13/Apr 2015
In the last month or two I’ve had basically the same conversation half a dozen times, both online and in real life, so I figured I’d just write up a blog post that I can refer to in the future.
The reason most high level languages are slow is usually because of two reasons:
- They don’t play well with the cache.
- They have to do expensive garbage collections
But really, both of these boil down to a single reason: the language heavily encourages too many allocations.
First, I’ll just state up front that for all of this I’m talking mostly about client-side applications. If you’re spending 99.9% of your time waiting on the network then it probably doesn’t matter how slow your language is – optimizing network is your main concern. I’m talking about applications where local execution speed is important.
I’m going to pick on C# as the specific example here for two reasons: the first is that it’s the high level language I use most often these days, and because if I used Java I’d get a bunch of C# fans telling me how it has value types and therefore doesn’t have these issues (this is wrong).
In the following I will be talking about what happens when you write idiomatic code. When you work “with the grain” of the language. When you write code in the style of the standard libraries and tutorials. I’m not very interested in ugly workarounds as “proof” that there’s no problem. Yes, you can sometimes fight the language to avoid a particular issue, but that doesn’t make the language unproblematic.
Cache costs review
First, let’s review the importance of playing well with the cache. Here’s a graph based on this data on memory latencies for Haswell:
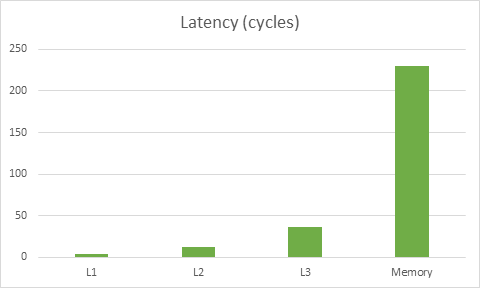
The latency for this particular CPU to get to memory is about 230 cycles, meanwhile the cost of reading data from L1 is 4 cycles. The key takeaway here is that doing the wrong thing for the cache can make code ~50x slower. In fact, it may be even worse than that – modern CPUs can often do multiple things at once so you could be loading stuff from L1 while operating on stuff that’s already in registers, thus hiding the L1 load cost partially or completely.
Without exaggerating we can say that aside from making reasonable algorithm choices, cache misses are the main thing you need to worry about for performance. Once you’re accessing data efficiently you can worry about fine tuning the actual operations you do. In comparison to cache misses, minor inefficiencies just don’t matter much.
This is actually good news for language designers! You don’t have to build the most efficient compiler on the planet, and you totally can get away with some extra overhead here and there for your abstractions (e.g. array bounds checking), all you need to do is make sure that your design makes it easy to write code that accesses data efficiently and programs in your language won’t have any problems running at speeds that are competitive with C.
Why C# introduces cache misses
To put it bluntly, C# is a language that simply isn’t designed to run efficiently with modern cache realities in mind. Again, I’m now talking about the limitations of the design and the “pressure” it puts on the programmer to do things in inefficient ways. Many of these things have theoretical workarounds that you could do at great inconvenience. I’m talking about idiomatic code, what the language “wants” you to do.
The basic problem with C# is that it has very poor support for value-based programming. Yes, it has structs which are values that are stored “embedded” where they are declared (e.g. on the stack, or inside another object). But there are a several big issues with structs that make them more of a band-aid than a solution.
You have to declare your data types as struct up front – which means that if you ever need this type to exist as a heap allocation then all of them need to be heap allocations. You could make some kind of class-wrapper for your struct and forward all the members but it’s pretty painful. It would be better if classes and structs were declared the same way and could be used in both ways on a case-by-case basis. So when something can live on the stack you declare it as a value, and when it needs to be on the heap you declare it as an object. This is how C++ works, for example. You’re not encouraged to make everything into an object-type just because there’s a few things here and there that need them on the heap.
Referencing values is extremely limited. You can pass values by reference to functions, but that’s about it. You can’t just grab a reference to an element in a List
, you have to store both a reference to the list and an index. You can’t grab a pointer to a stack-allocated value, or a value stored inside an object (or value). You can only copy them, unless you’re passing them to a function (by ref). This is all understandable, by the way. If type safety is a priority, it’s pretty difficult (though not imposible) to support flexible referencing of values while also guaranteeing type safety. The rationale behind these restrictions don’t change the fact that the restrictions are there, though. Fixed sized buffers don’t support custom types and also requires you to use an unsafe keyword.
Limited “array slice” functionality. There’s an ArraySegment class, but it’s not really used by anyone, which means that in order to pass a range of elements from an array you have to create an IEnumerable, which means allocation (boxing). Even if the APIs accepted ArraySegment parameters it’s still not good enough – you can only use it for normal arrays, not for List
, not for stack-allocated arrays, etc.
The bottom line is that for all but very simple cases, the language pushes you very strongly towards heap allocations. If all your data is on the heap, it means that accessing it is likely to cause a cache misses (since you can’t decide how objects are organized in the heap). So while a C++ program poses few challenges to ensuring that data is organized in cache-efficient ways, C# typically encourages you to allocate each part of that data in a separate heap allocation. This means the programmers loses control over data layout, which means unnecessary cache misses are introduced and performance drops precipitously. It doesn’t matter that you can now compile C# programs natively ahead of time – improvement to code quality is a drop in the bucket compared to poor memory locality.
Plus, there’s storage overhead. Each reference is 8 bytes on a 64-bit machine, and each allocation has its own overhead in the form of various metadata. A heap full of tiny objects with lots of references everywhere has a lot of space overhead compared to a heap with very few large allocations where most data is just stored embedded within their owners at fixed offsets. Even if you don’t care about memory requirements, the fact that the heap is bloated with header words and references means that cache lines have more waste in them, this in turn means even more cache misses and reduced performance.
There are sometimes workarounds you can do, for example you can use structs and allocate them in a pool using a big List
Finally, I want to point out that this isn’t just an issue for “hot spot” code. Idiomatically written C# code tends to have classes and references basically everywhere. This means that all over your code at relatively uniform frequency there are random multi-hundred cycle stalls, dwarfing the cost of surrounding operations. Yes there could be hotspots too, but after you’ve optimized them you’re left with a program that’s just uniformly slow. So unless you want to write all your code with memory pools and indices, effectively operating at a lower level of abstraction than even C++ does (and at that point, why bother with C#?), there’s not a ton you can do to avoid this issue.
Garbage Collection
I’m just going to assume in the following that you already understand why garbage collection is a performance problem in a lot of cases. That pausing randomly for many milliseconds just is usually unacceptable for anything with animation. I won’t linger on it and move on to explaining why the language design itself exacerbates this issue.
Because of the limitations when it comes to dealing with values, the language very strongly discourages you from using big chunky allocations consisting mostly of values embedded within other values (perhaps stored on the stack), pressuring you instead to use lots of small classes which have to be allocated on the heap. Roughly speaking, more allocations means more time spent collecting garbage.
There are benchmarks that show how C# or Java beat C++ in some particular case, because an allocator based on a GC can have decent throughput (cheap allocations, and you batch all the deallocations up). However, this isn’t a common real world scenario. It takes a huge amount of effort to write a C# program with the same low allocation rate that even a very naïve C++ program has, so those kinds of comparisons are really comparing a highly tuned managed program with a naïve native one. Once you spend the same amount of effort on the C++ program, you’d be miles ahead of C# again.
I’m relatively convinced that you could write a GC more suitable for high performance and low latency applications (e.g. an incremental GC where you spend a fixed amount of time per frame doing collection), but this is not enough on its own. At the end of the day the biggest issue with most high level languages is simply that the design encourages far too much garbage being created in the first place. If idiomatic C# allocated at the same low rate a C program does, the GC would pose far fewer problems for high performance applications. And if you did have an incremental GC to support soft real-time applications, you’ll probably need a write barrier for it – which, as cheap as it is, means that a language that encourages pointers will add a performance tax to the mutators.
Look at the base class library for .Net, allocations are everywhere! By my count the .Net Core Framework contains 19x more public classes than structs, so in order to use it you’re very much expected to do quite a lot of allocation. Even the creators of .Net couldn’t resist the siren call of the language design! I don’t know how to gather statistics on this, but using the base class library you quickly notice that it’s not just in their choice of value vs. object types where the allocation-happiness shines through. Even within this code there’s just a ton of allocations. Everything seems to be written with the assumption that allocations are cheap. Hell, you can’t even print an int without allocating! Let that sink in for a second. Even with a pre-sized StringBuilder you can’t stick an int in there without allocating using the standard library. That’s pretty silly if you ask me.
This isn’t just in the standard library. Other C# libraries follow suit. Even Unity (a game engine, presumably caring more than average about performance issues) has APIs all over the place that return allocated objects (or arrays) or force the caller to allocate to call them. For example, by returning an array from GetComponents, they’re forcing an array allocation just to see what components are on a GameObject. There are a number of alternative APIs they could’ve chosen, but going with the grain of the language means allocations. The Unity folks wrote “Good C#”, it’s just bad for performance.
Closing remarks
If you’re designing a new language, please consider efficiency up front. It’s not something a “Sufficiently Smart Compiler” can fix after you’ve already made it impossible. Yes, it’s hard to do type safety without a garbage collector. Yes, it’s harder to do garbage collection when you don’t have uniform representation for data. Yes, it’s hard to reason about scoping rules when you can have pointers to random values. Yes, there are tons of problems to figure out here, but isn’t figuring those problems out what language design is supposed to be? Why make another minor iteration of languages that were already designed in the 1960s?
Even if you can’t fix all these issues, maybe you can get most of the way there? Maybe use region types (a la Rust) to ensure safety. Or maybe even consider abandoning “type safety at all costs” in favor of more runtime checks (if they don’t cause extra cache misses, they don’t really matter… and in fact C# already does similar things, see covariant arrays which are strictly speaking a type system violation, and leads to a runtime exception).
The bottom line is that if you want to be an alternative to C++ for high performance scenarios, you need to worry about data layout and locality.